
A few weeks ago, Lee Robinson wrote about migrating cursor.com from a headless CMS back to raw code and Markdown. The migration took three days, cost $260 in tokens, and deleted 322,000 lines of code. Their CMS CDN bill alone was $56,848.
The line that stuck with me was simple: content is just code.
I have been building GitCMS around that idea for the past year, but the more I work on it, the less it feels like a slogan and the more it feels like a description of reality. Content is text. Text lives well in files. Files belong in Git. And now that AI agents are becoming part of the editing process, the old CMS abstraction feels heavier than it used to.
This is not an argument that every database-backed CMS is broken. It is an argument that the center of gravity has moved.
The Two Models
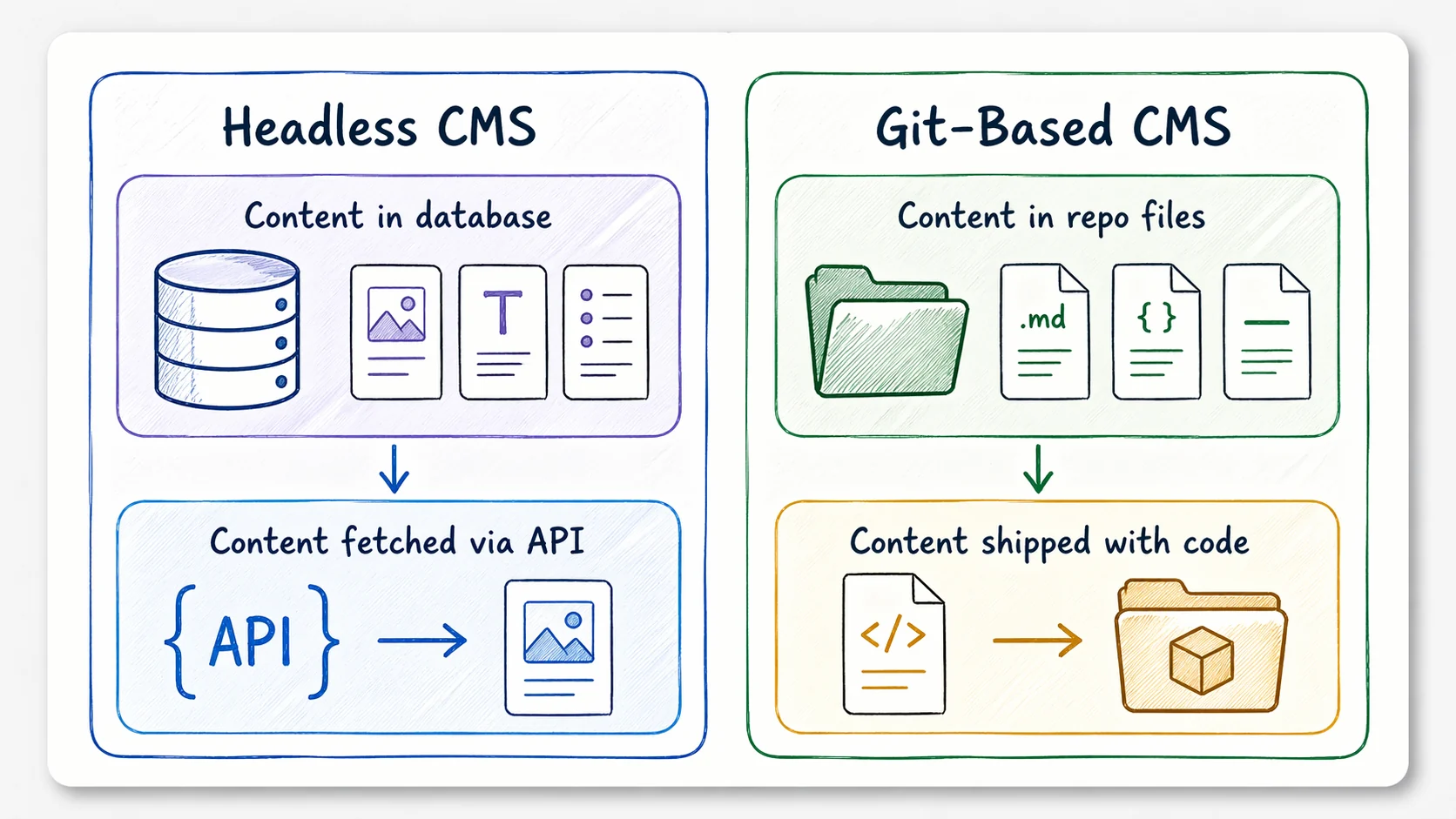
There are really two ways to think about content.
Headless CMS tools like Contentful, Sanity, Strapi, WordPress, and Payload store content in a centralized system and expose it through APIs. Content is separated from presentation, and editors work through a dashboard.
Git-based CMS tools store content as files in your Git repository. Markdown, MDX, YAML, JSON, frontmatter, the repo is the source of truth, and Git history becomes the editorial record.
That tradeoff used to be about convenience versus structure. Now I think it is more about friction versus fit.
Why AI Changes the Equation
AI agents are good at files, diffs, and repositories. They are less natural when the same content is trapped behind a dashboard and a set of API calls.
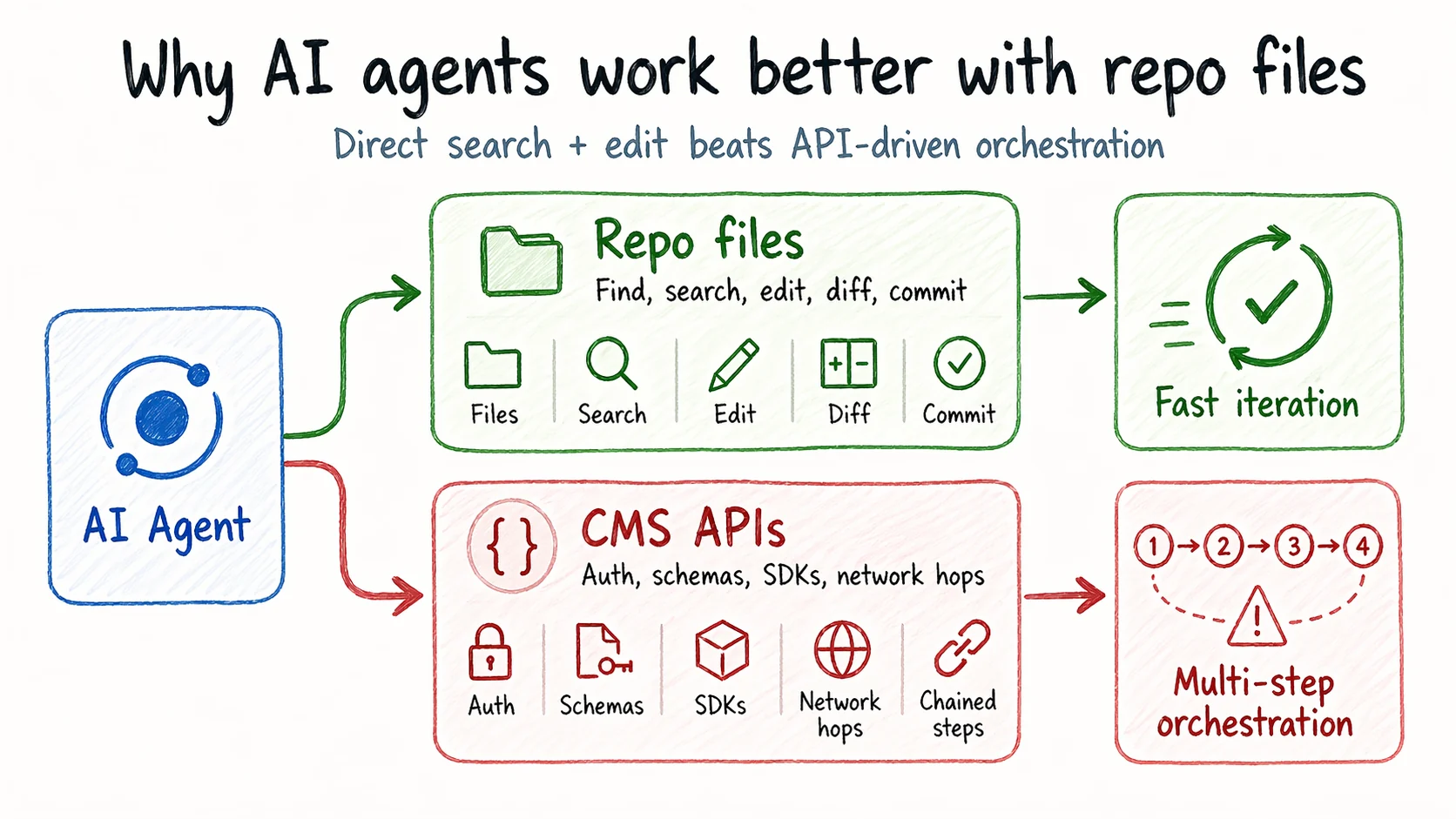
When content lives in files, an agent can search the repo, rewrite a paragraph, open a branch, and leave the change as a diff another human can review.
When content lives behind a CMS API, the same job usually turns into a sequence of extra steps:
- authenticate
- learn the provider's schema
- make a network request
- translate the result back into the codebase
That is the real cost. Not just latency, but context loss. The agent cannot simply look at the repo and understand the content in the same way it can understand code.
That is why the Cursor migration mattered to me. Their move was not just about deleting tooling. It was about removing a layer that no longer helped them move faster.
Why Git Keeps Winning
Version control is editorial history
Every edit, every rollback, every "who changed this and when" lives in git log. That is not a hidden revision system inside a product dashboard. It is the same history developers already trust for code.
Branches make drafting natural
Want to draft without touching production? Use a branch. Want a review? Open a PR. Want comments? Git already has the workflow. Content fits Git because Git was designed for collaborative change.
Code and content stop drifting apart
If a feature needs a docs update, that should be one change, not two disconnected systems and two separate release paths. The tighter the coupling between content and product, the less room there is for drift.
Portability is the default
Markdown files are not a proprietary format. If the CMS goes away, the content remains. That matters more than people admit, especially for teams that expect content to outlive tools.
The economics are simpler
Database-backed CMSs can look cheap at the start and become expensive as seats, bandwidth, storage, and usage grow. Files in a repo are a much simpler cost model.
The Honest Downsides
I'm biased, but I'm not going to pretend Git-based CMS is perfect for everyone. Here's where database CMSs genuinely win:
Non-technical editors
If your content team has never seen a terminal, a database CMS with a polished GUI is more approachable. Git concepts like branches, commits, and merge conflicts can be intimidating. This is exactly why I built GitCMS with a visual Notion-like editor on top of an editorial workflow that hides the Git terminology — to close this gap. But the gap may exists with other git based cms.
Real-time collaboration
Google Docs-style simultaneous editing? Headless CMSs can do this because they control the persistence layer. Git-based workflows are inherently asynchronous — you commit, push, and merge. For most content workflows this is fine, and arguably better for quality, but if you need multiple people editing the same paragraph simultaneously, a headless CMS handles it more naturally.
Deep relational models
If your content model has deep relationships — a product references a category which references a tag taxonomy which references a localization bundle — a headless CMS with structured types is purpose-built for this. File-based content can model relationships, but it is more manual and less enforceable.
Dynamic content at scale
If you need real-time personalized content served to millions of users with A/B testing and audience segmentation, you probably need a database behind an API. Static files served from a CDN do not do dynamic content selection.
Why It's Still Worth Going Git-Based
Here's my take as someone who's been building this for a year: the downsides are real, and they are also shrinking.
Visual editors like GitCMS are solving the non-technical-editor problem. You do not need to know Git to use a Notion-like editor that commits behind the scenes. For content, async is usually better anyway. A PR review catches more issues than two people typing in the same doc.
The deep-relationships argument matters, but most indie projects, blogs, docs sites, and marketing pages are not relational databases in disguise. They have posts, pages, and images. Files handle that perfectly.
Meanwhile, the upside keeps compounding. AI agents are getting better at working with files every month. Static site generators are getting more powerful. Edge deployment keeps making static content faster. Git-based workflows are becoming the default for more than just code.
Start on Day 0

If you are building a product, do not treat content as a phase-two problem. Start the blog, docs, or launch content on day 0. Not because SEO is magical, but because content compounds and the workflow gets harder to fix later.
A Git-based CMS makes that easier. Point a collection at content/blog, keep everything next to the code, and let the same repo handle writing, review, and deploys. There is no separate database to manage and no extra system to keep in sync.
If your stack is Astro, Next.js, Hugo, Nuxt, SvelteKit, Eleventy, Jekyll, Gatsby, Docusaurus, VuePress, or MkDocs, that setup can usually be done quickly.
What I Built and Why
I built GitCMS because I wanted the Git model without making writers think like developers. The point was never "Git for Git's sake." The point was to keep the content in the repo, keep the workflow visible, and make the editor feel natural enough that people would actually use it.
Git is the source of truth. Every save becomes a commit. The editor stays visual. AI can work against the same files humans do. One repo can hold multiple sites and collections.
That is what I mean when I say content is code. Not that content is software in a literal sense, but that it deserves the same discipline, versioning, and workflow as the rest of the product.
The Direction Things Are Moving
Cursor moved away from a CMS. Their reasoning, paraphrased, was that abstractions are more expensive now because AI makes the cost of indirection easier to feel.
I think that is the real story. As AI agents become part of the editing workflow, the tools that win will be the ones that put content where agents can actually reach it: in files, in repos, in code.
Git already won that argument for software. I think it is now winning it for content too.
GitCMS is live now. If you're building with a static site generator and want a visual editor that commits to your repo, give it a try.